Comparing rule-based methods and pre-trained language models to classify flood related Tweets

Social media presents a rich source of real-time information provided by individual users in emergency situations. However, due to its unstructured nature and high volume, it is challenging to extract key information from these continuous data streams. This paper compares the ability to identify relevant flood related Tweets between a deep neural classification model known as a transformer, and a simple rule-based classification. Results show that the classification model out-performs the rule-based approach, at the time-cost of labelling and training the model.
social media, natural language processing, social interaction
Introduction
Twitter presents large continuous feed of information regarding emergency events, contributed through individual users, as these events occur. Many emergency events have been studied in relation to Twitter, including hurricanes and floods in the US (Hughes et al. 2014; Kim and Hastak 2018), Paris terror attacks in 2015 (Reilly and Vicari 2021), and UK flooding events (Saravanou et al. 2015; Brouwer et al. 2017).
Extreme weather events have become increasingly common (Kron, Löw, and Kundzewicz 2019), a trend that is expected to continue (Forzieri et al. 2017), meaning there is an increasing demand to predict and understand how natural disasters develop. Tweets have proved useful in complementing and supporting emergency response in many cases, and often the first reports about emergencies on social media often precede those of mainstream media (Perng et al. 2013; Martínez-Rojas, Pardo-Ferreira, and Rubio-Romero 2018; Kim and Hastak 2018; Laylavi, Rajabifard, and Kalantari 2016). It is therefore important to be able to extract flood related Tweets, removing the noise that often comes with social media streams (Ashktorab et al. 2014).
Much of the past work that has used Twitter to study past emergency events has used keywords to identify relevant Tweets (Kryvasheyeu et al. 2016; Brouwer et al. 2017; Morstatter et al. 2013). This however has several issues, keywords are human selected, meaning they require a pre-existing knowledge of the semantics used to describe targeted events. Certain keywords also do not always relate to these emergency events (Sakaki, Okazaki, and Matsuo 2010; Spielhofer et al. 2016), for example a person may be in ‘floods of tears’. Finally, Tweets relevant to emergency events also do not necessarily contain an obvious keyword (‘Cars are floating down the street!’), and therefore are unable to be detected. More recent work has considered the ability to use machine learning to classify Tweets into those relevant to emergency events, and those that are irrelevant (Imran et al. 2020; Arthur et al. 2018; Sakaki, Okazaki, and Matsuo 2010; Li et al. 2018). These studies have utilised a variety of methods, building from classical approaches like Naïve Bayes classification (Imran et al. 2013; Li et al. 2018) and Support Vector Machines (SVMs) (Caragea et al. 2011; Sakaki, Okazaki, and Matsuo 2010), while more recent work has considered the emerging prevalence of neural networks in text-based classification (Caragea, Silvescu, and Tapia 2016; de Bruijn et al. 2020; Nguyen et al. 2017). Traditional machine learning methods however rely on the use of feature engineering to determine model input, are unable to preserve word order, and have limited capability to use context, often over-fitting based on features selected (Caragea, Silvescu, and Tapia 2016). Work with neural networks has shown that given pre-trained word embeddings, they have the capability to outperform these methods (Ghafarian and Yazdi 2020; Caragea, Silvescu, and Tapia 2016; Algiriyage and Prasanna 2021).
This work considers the retrospective classification of a selection of Tweets from past flooding events in the United Kingdom, evaluating the effectiveness of a neural classification model called a transformer against a keyword based approach. This work aims to demonstrate the benefits and costs of the use of new sophisticated methods in natural language processing for this task. Further work is expected to build on this, allowing for information extraction from the relevant Tweets to inform first responders, providing more fine-grained information based on the first-hand experience of individuals like specific property damage, or missing persons, allowing social media to complement existing methods used during flood events [muller2015].
Methodology
Data Collection
Flood Data
A historical dataset containing all Severe Flood Warnings, Flood Warnings, and Flood Alerts issued by the UK flood warning system is available through the UK Government under the Open Government Licence. This data was linked with flood zones from the Environment Agency Real Time Flood-Monitoring API. To reduce the volume of flood events being considered, only Severe Flood Warnings occurring after 2010 were selected, leaving a total of 314 individual Severe Flood Warning events.
Tweets
The Twitter API v2 was used to extract Tweets from the full historic Tweet archive. For each flood warning the query was constructed using several requirements:
- Time-frame: 7 days before to 7 days after flood warning
- Bounds: Bounding box of the relevant flood area
- Parameters: has geography, exclude retweets, exclude replies, exclude quotes
Geographic information associated with every Tweet was required due to the decision to use bounding boxes to pre-emptively filter Tweets in areas not subject to flooding. The new Twitter API now uses a combination of factors to associate geographic coordinates with Tweets which overcomes the issues with limited availability of geotags found with many previous studies (Middleton, Middleton, and Modafferi 2014; Carley et al. 2016; Morstatter et al. 2013). Geography associated with a Tweet may now include either geotags, user profile location or locations mentioned in Tweet. The total number of Tweets extracted was 89,864, with an average of 286 Tweets per flood warning. From this corpus, only a random subset of ~2,500 Tweets were considered for training and evaluation, selecting a subset that balances time constraints and mirroring the corpus size of past work (Caragea, Silvescu, and Tapia 2016; Ghafarian and Yazdi 2020).
Classification
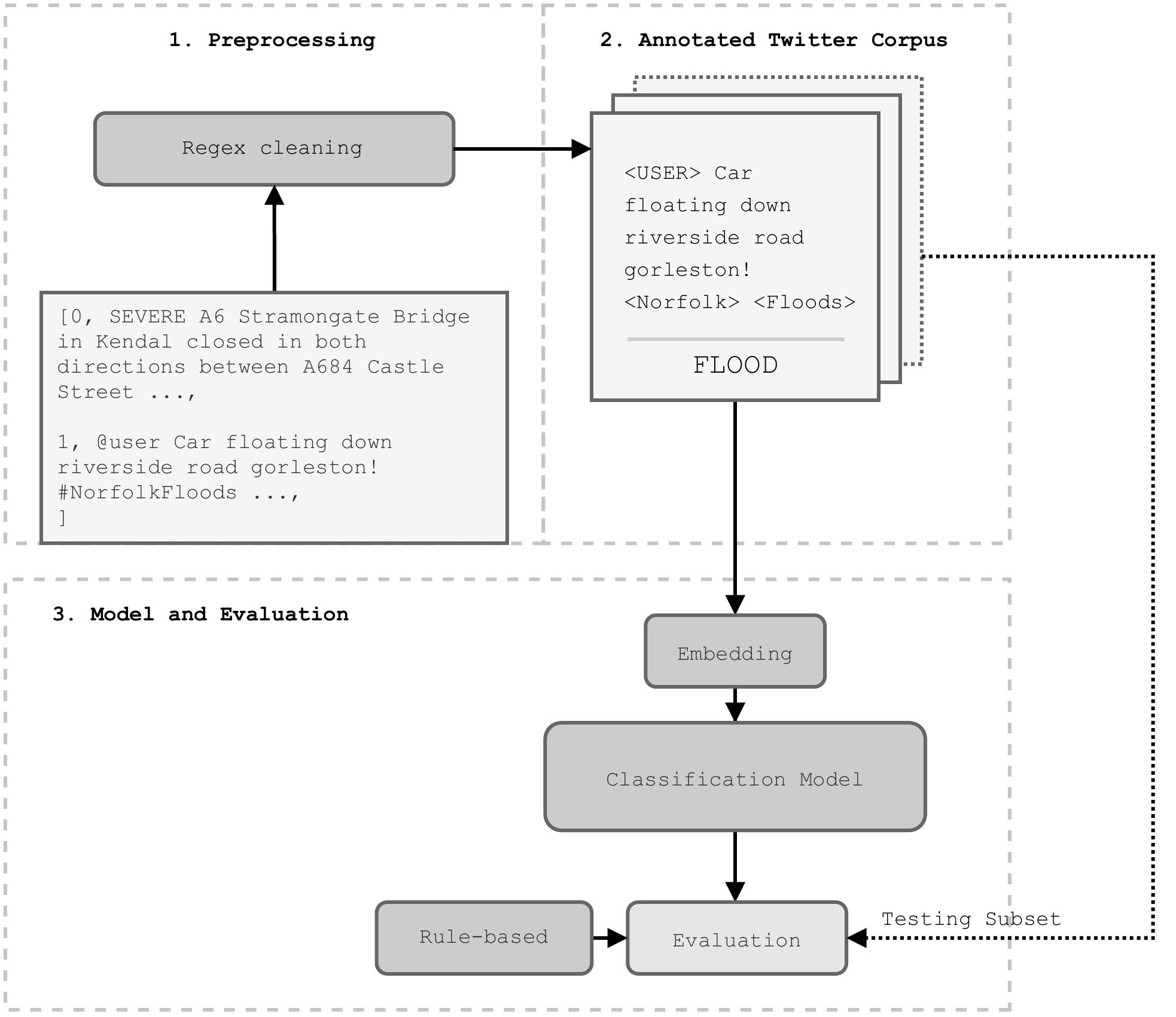
Figure 1 gives an overview of the classification pipeline used, each Tweet was first pre-processed to normalise usernames and web addresses, and hashtags were parsed to extract words (Pota et al. 2020) (Stage 1). The selected ~2,500 Tweets were manually annotated to train the classification model using Doccano (Nakayama et al. 2018), with 20% used for model validation (Stage 2). The validation subset was then used to evaluate model performance in relation to the simple rule-based approach (Stage 3).
The model builds on the established NLP task of sequence classification, taking token sequences (\(\mathbf{x} = \{x_{0}, x_{1}\dots x_{n}\}\)), and predicting a single label (\(\mathit{y}\)). A pre-trained transformer language model based on the RoBERTa architecture was used as a base, pre-trained using a corpus of 58 million Tweets (Barbieri et al. 2020)1.
To construct a rule-based approach for evaluation against this model, Tweets from the validation subset that included a selection of 456 keywords provided by (Saravanou et al. 2015) were labelled as being flood related (FLOOD), while all Tweets that did not contain this selection of keywords were labelled as NOT_FLOOD.
For comparative evaluation, the F1 metric was used, which takes the harmonic mean of the precision and recall, meaning class imbalance is accounted for. To qualitatively assess the performance of the transformer model, attributions2 for each word in a few selected Tweets were visualised to identify the ability of the model to capture information relevant to flood events, without having to explicitly be fed in keywords (Sundararajan, Taly, and Yan 2017).
Overall the classification model out-performed the rule-based method on the validation subset, achieving an F1 score of 0.938, compared with 0.814 for the rule-base approach. There is both a lower recall for the rule-based model (0.905 compared with 0.952), and a lower precision (0.952 compared with 0.988).
Figure 2 explores the decisions made by the transformer model, using four example Tweets to demonstrate the attribution given to each token when assigning a label. Figure \(\ref{fig:transformerviz}\) (A) first gives an example Tweet that is correctly identified as being flood related by the transformer, but does not contain any selected flood related keywords. In this example three keywords are highlighted as important by the model for its correct classification gravel, river and wier. This suggests that the model is able to infer from context that these words relate to flooding, rather than having to be explicitly told through feature engineering or keywords.
On Figure 2 (B), an example is chosen where the model was able to correctly identify the Tweet as being unrelated to flooding, but contains the keyword lightning meaning the rule-based method incorrectly identified it as flood related. Several keywords again appear important for this correct classification, finally which is unlikely to appear in Tweets relevant to floods, in addition to apples and ipad pro, both of which likely appear relatively frequently on Twitter, but rarely in flood related contexts.
The final two sub-figures give examples where the model gives incorrect classifications, but the rule-based method does not. Figure 2 (C) shows that while the model realises that raining is a word positively associated with flooding, the rest of the sentence implies that the overall Tweet is likely not in reference to a flooding event. This example reflects a potential issue with selecting a broad annotation scheme, which considered mentions of weather that may relate to flooding events to be a positive match. A Tweet like this is relatively borderline, even for human annotation, meaning it is unsurprising that the model struggles to make a correct decision. This issue is also reflected in Figure 2 (D), the words tide, mark and kent are all identified as flood related words, which is likely true and the label reflects an issue with human annotation.
Discussion
While the transformer-based classification model outperforms a rule-based approach, they present different benefits and costs. Supervised classification through a neural network relies heavily on a suitable amount of high quality labelled data, which presents an initial time-cost. Keyword selection is comparatively straightforward, and does not rely on a pre-existing corpus of relevant text. The training and inference for the transformer model also costs both time and resources, while keyword selection may be applied directly during the extraction of Tweets through the Twitter API.
Keywords however are inherently subjective, as demonstrated by past work which found varying selections of keywords to be appropriate the classification of flood related Tweets (Spielhofer et al. 2016; Arthur et al. 2018; Saravanou et al. 2015). Constructing a labelled corpus a broad binary classification of Tweets to train a supervised model is less subjective, as the model itself may use the context provided through the training data to independently learn how to approach the classifications. This increased complexity means, through higher recall and precision, the model approach retrieves more relevant information, while ignoring a higher proportion of irrelevant information.
The complexity of the transformer architecture itself also presents improvements over past machine learning methods, as word order is preserved, and the pre-trained word embeddings mean no ad hoc feature engineering is required, which may have contributed to some bias and over-fitting in past work (Caragea, Silvescu, and Tapia 2016). Appropriate use of semantic context is a particular benefit of the transformer architecture over simpler deep learning methods, notable on Figure 2 (B), which indicates that while lightning is likely considered by the model in most contexts to be associated with floods, the model is able to consider this instance independently, understanding that in this context the word ‘lightning’ is not weather related. Further work should consider using the entire corpus of 89,864 Tweets extracted relating to UK flood events to train a more robust model.
References
Footnotes
Available on the Huggingface Model Hub (Wolf et al. 2020)↩︎
https://github.com/cdpierse/transformers-interpret↩︎
Citation
@inproceedings{berragan2022,
author = {Berragan, Cillian and Singleton, Alex and Calafiore, Alessia
and Morley, Jeremy},
title = {Comparing Rule-Based Methods and Pre-Trained Language Models
to Classify Flood Related {Tweets}},
booktitle = {30th GISRUK Conference 2022},
date = {2022-03-29},
url = {https://zenodo.org/records/6411499/files/GISRUK_2022_paper_45.pdf},
doi = {10.5281/zenodo.6411499},
langid = {en}
}